
Co to jest baza danych? Podstawowe pojęcia
Baza danych to uporządkowany zbiór informacji przechowywanych elektronicznie w systemie komputerowym. Za zarządzanie nią odpowiada DBMS (Database Management System) - system zarządzania bazą danych, który kontroluje sposób przechowywania, organizacji i pobierania danych.
Kluczowe elementy każdej bazy danych to:
- Schemat - struktura określająca sposób organizacji danych
- Dane - rzeczywiste informacje przechowywane w bazie
- Zapytania - mechanizmy umożliwiające wyszukiwanie i modyfikację danych
- Metadane - informacje opisujące strukturę i właściwości danych
Dlaczego wybór typu bazy ma znaczenie
Różne typy baz danych zostały zaprojektowane z myślą o różnych zastosowaniach. Relacyjne bazy danych doskonale sprawdzają się w systemach transakcyjnych wymagających silnej spójności, NoSQL radzi sobie z big data i aplikacjami wymagającymi elastyczności, a bazy wektorowe są niezbędne w nowoczesnych rozwiązaniach AI i wyszukiwaniu semantycznym.
Wybór niewłaściwego typu może prowadzić do problemów z wydajnością, trudności w skalowaniu czy ograniczeń funkcjonalnych, które ujawnią się dopiero w fazie produkcyjnej.
SQL od zera — kurs SkumajBazy
Naucz się SQL w praktyce. Kurs przeznaczony dla osób bez doświadczenia z bazami danych.
- ✓24 lekcje wideo + 80 ćwiczeń
- ✓Realne bazy z e-commerce
- ✓Społeczność i code-review
Sprawdź, gdzie AI realnie pomoże w Twojej firmie
Bezpłatna rozmowa diagnostyczna online. Jeden konkretny proces albo problem, zero sprzedażowej prezentacji.
Wybierz dogodny termin bezpłatnej rozmowy (30 min).
Umów bezpłatną rozmowęRelacyjne bazy danych (SQL)
Definicja i cechy
Relacyjne bazy danych opierają się na modelu relacyjnym, gdzie dane są organizowane w tabele składające się z wierszy i kolumn. Każda tabela reprezentuje określony typ encji, a relacje między tabelami są definiowane za pomocą kluczy obcych.
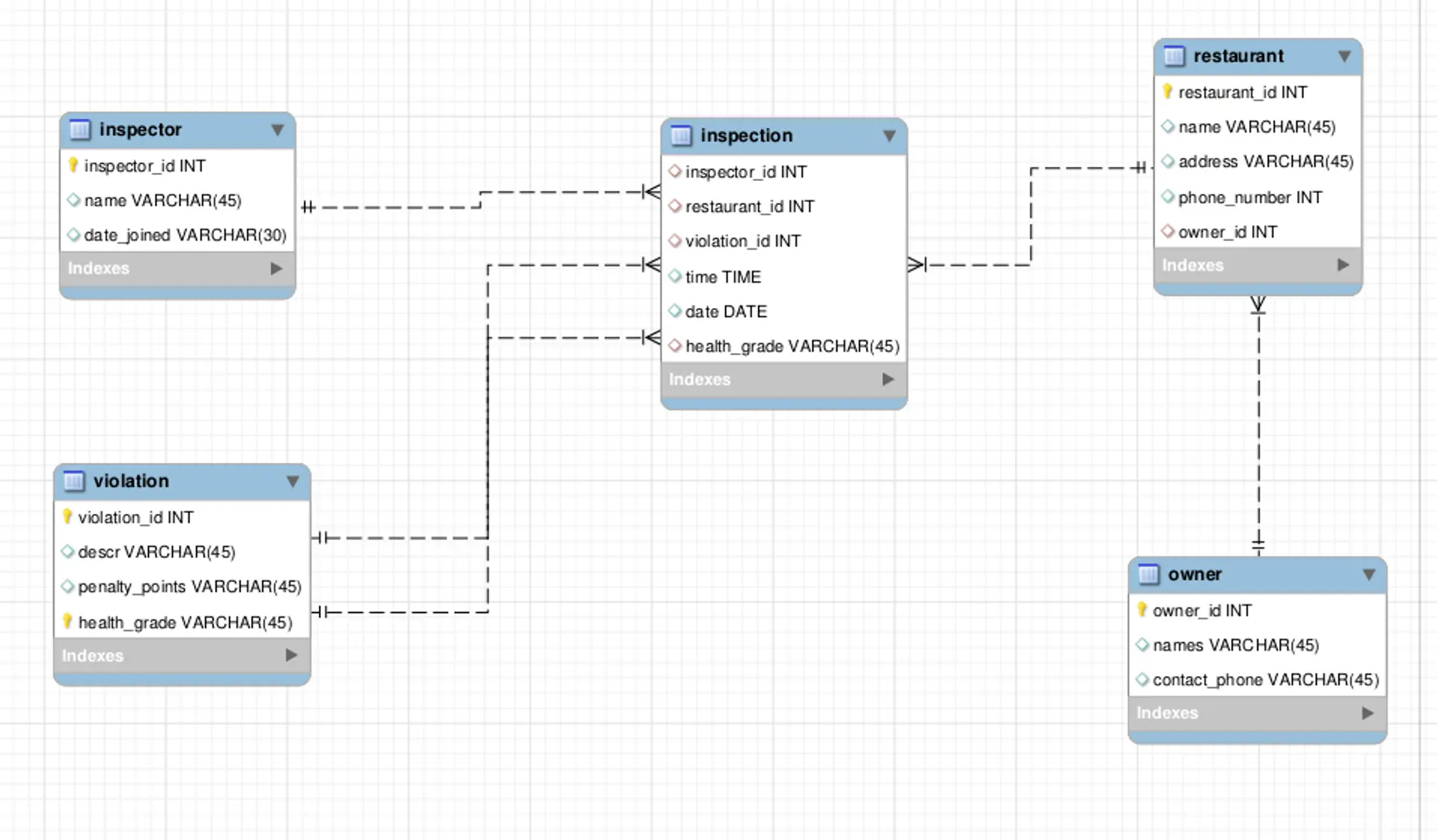 . Zobacz też ten artykuł, w którym poruszamy temat różnych baz danych: SQL dla początkujących - czym jest SQL oraz różnice między MySQL, PostgreSQL i SQLite
. Zobacz też ten artykuł, w którym poruszamy temat różnych baz danych: SQL dla początkujących - czym jest SQL oraz różnice między MySQL, PostgreSQL i SQLite
Główne cechy relacyjnych baz danych:
- Sztywny schemat - struktura musi być zdefiniowana przed wprowadzeniem danych
- SQL (Structured Query Language) - standardowy język zapytań
- Właściwości ACID - gwarantujące spójność transakcji
- Normalizacja - eliminowanie redundancji danych
Właściwości ACID to fundament relacyjnych baz danych:
- Atomicity (Niepodzielność) - transakcja jest wykonywana w całości lub wcale
- Consistency (Spójność) - dane pozostają zgodne z regułami biznesowymi
- Isolation (Izolacja) - równoczesne transakcje nie wpływają na siebie
- Durability (Trwałość) - zatwierdzone zmiany są trwale zapisane
Przykładowe bazy: PostgreSQL, MySQL, Oracle
PostgreSQL wyróżnia się jako obiektowo-relacyjny system o wysokiej niezawodności. Oferuje zaawansowane typy danych, wsparcie dla JSON i rozszerzenia jak pgvector do obsługi wektorów. Jest szczególnie ceniony za swoją rozszerzalność i zgodność ze standardami SQL.
MySQL to popularne rozwiązanie open-source, szczególnie rozpowszechnione w aplikacjach webowych. Charakteryzuje się prostotą konfiguracji i dobrą wydajnością przy operacjach odczytu.
Oracle reprezentuje najbardziej zaawansowane komercyjne rozwiązanie relacyjne, oferujące rozbudowane funkcje analityczne, wysoką dostępność i wsparcie dla dużych przedsiębiorstw.
Zalety i wady relacyjnych baz danych
Zalety:
- Dojrzałość technologii - dziesiątki lat rozwoju i optymalizacji
- Silna spójność danych dzięki właściwościom ACID
- Standardowy język SQL znany przez większość programistów
- Zaawansowane możliwości zapytań z JOINami i agregacjami
- Bogaty ekosystem narzędzi i wsparcia technicznego
Wady:
- Ograniczona skalowalność pozioma - trudności z rozpraszaniem danych
- Sztywny schemat utrudniający adaptację do zmieniających się wymagań
- Problemy z obsługą różnorodnych typów danych (multimedia, dokumenty)
- Wyższe koszty skalowania pionowego
Nierelacyjne bazy danych (NoSQL)
Typy: dokumentowe, klucz-wartość, kolumnowe, grafowe
NoSQL to rodzina baz danych zaprojektowanych z myślą o elastyczności, skalowalności i obsłudze różnorodnych typów danych. Wyróżniamy cztery główne kategorie:
Diagram showing four main types of NoSQL databases: key-value, wide-column, graph, and document.
Bazy dokumentowe przechowują dane w formie dokumentów (zwykle JSON). MongoDB to najpoznawszy przykład, oferujący elastyczność schematu i intuicyjny model danych przypominający obiekty w kodzie aplikacji.
Bazy klucz-wartość to najprostszy model NoSQL, gdzie każda wartość jest identyfikowana unikalnym kluczem. Redis to popularna implementacja, często używana jako cache lub do przechowywania sesji użytkowników.
Bazy kolumnowe organizują dane w rodziny kolumn zamiast wierszy. Apache Cassandra to lider w tej kategorii, zapewniający wysoką dostępność i linearną skalowalność dla big data.
Bazy grafowe specjalizują się w przechowywaniu i analizowaniu relacji między encjami. Neo4j doskonale sprawdza się w analizie sieci społecznościowych, systemach rekomendacji czy wykrywaniu oszustw.
Przykładowe bazy: MongoDB, Cassandra, Redis, Neo4j
MongoDB zyskało popularność dzięki elastycznemu modelowi dokumentowemu. Umożliwia przechowywanie zagnieżdżonych struktur danych i oferuje bogate możliwości zapytań, zachowując przy tym możliwość poziomego skalowania.
Apache Cassandra wykorzystuje architekturę peer-to-peer bez pojedynczych punktów awarii. Zapewnia liniową skalowalność i wysoką dostępność, co czyni ją idealną do aplikacji IoT i systemów big data.
Redis to baza danych w pamięci oferująca struktury danych jak listy, zbiory czy mapy hash. Jej wyjątkowa szybkość (operacje w mikrosekundach) sprawia, że jest niezastąpiona w aplikacjach wymagających niskiej latencji.
Neo4j to lider wśród baz grafowych, oferujący język zapytań Cypher do analizy połączeń i wzorców w danych. Znajduje zastosowanie w systemach antyfraudowych, analizie sieci społecznościowych i systemach rekomendacji.
SkumajBazy — SQL dla każdego
Kurs SQL z praktycznymi zadaniami, quizami i projektami końcowymi. Idealne przygotowanie do rozmów kwalifikacyjnych.
- ✓24 lekcje wideo + 80 ćwiczeń
- ✓Realne bazy z e-commerce
- ✓Społeczność i code-review
Zalety i wady NoSQL
Zalety:
- Elastyczność schematu - łatwa adaptacja do zmieniających się wymagań
- Skalowalność pozioma - możliwość dodawania serwerów zamiast ich upgrade'u
- Wysoka wydajność przy określonych typach operacji
- Obsługa różnorodnych typów danych - dokumenty, grafy, multimedia
- Ekonomiczność - często bazują na standardowym sprzęcie
Wady:
- Eventual consistency zamiast silnej spójności
- Brak standardowego języka zapytań - każda baza ma własne API
- Ograniczone możliwości transakcji między różnymi dokumentami/kolekcjami
- Mniejsza dojrzałość ekosystemu w porównaniu do SQL
Bazy wektorowe (Vector Databases)
Co to jest baza wektorowa - embeddingi, podobieństwo, wyszukiwanie semantyczne
Bazy wektorowe to specjalistyczne systemy przechowywania zaprojektowane do obsługi wektorów (embeddingów) - wielowymiarowych reprezentacji matematycznych różnych typów danych. Embeddingi mogą reprezentować tekst, obrazy, dźwięk czy inne dane, umożliwiając wyszukiwanie semantyczne oparte na podobieństwie znaczeniowym, a nie tylko na dopasowaniu słów kluczowych.
Conceptual diagram of multimodal embeddings integrating images, audio, text, and other data types for vector similarity search.
Kluczowe cechy baz wektorowych:
- Przechowywanie wektorów wysokowymiarowych (często 512-1536 wymiarów)
- Algorytmy wyszukiwania podobieństwa (cosine similarity, Euclidean distance)
- Indeksowanie wektorowe (HNSW, IVF) dla szybkich zapytań
- Obsługa metadanych do filtrowania wyników
Najpopularniejsze narzędzia/przykłady
Pinecone to w pełni zarządzana usługa chmurowa skupiająca się na prostocie użytkowania. Oferuje automatyczne skalowanie i SLA dla latencji, ale wiąże się z uzależnieniem od dostawcy (vendor lock-in).
Weaviate łączy wyszukiwanie wektorowe z możliwościami grafowymi. Jego atutem jest wsparcie dla hybrydowych zapytań łączących wyszukiwanie semantyczne z filtrami metadanych oraz wbudowane moduły do wektoryzacji tekstu i obrazów.
Milvus to open-source'owe rozwiązanie zaprojektowane z myślą o dużej skali. Oferuje rozproszoną architekturę oddzielającą storage, compute i metadata, co umożliwia obsługę miliardów wektorów.
pgvector to rozszerzenie PostgreSQL dodające funkcjonalności wektorowe. Pozwala na wykorzystanie istniejącej infrastruktury SQL przy jednoczesnym dodaniu możliwości AI/ML.
Zastosowania: rekomendacje, semantyczne wyszukiwanie, AI, RAG, automatyzacja
Bazy wektorowe rewolucjonizują sposób, w jaki systemy rozumieją i przetwarzają informacje:
Wyszukiwanie semantyczne umożliwia znajdowanie dokumentów na podstawie znaczenia, nie tylko słów kluczowych. Zamiast szukać "samochód", system znajdzie także dokumenty o "pojazdach" czy "autach".
Systemy rekomendacji wykorzystują podobieństwo między embeddingami użytkowników i produktów do generowania spersonalizowanych sugestii. E-commerce może rekomendować produkty na podstawie historii zakupów i preferencji.
Diagram showing user and product embeddings feeding into a recommender engine and a vector database for indexing, illustrating vector database use in AI recommendations.
RAG (Retrieval-Augmented Generation) łączy bazy wektorowe z dużymi modelami językowymi. System najpierw wyszukuje relevantne dokumenty, a następnie wykorzystuje je do generowania odpowiedzi, co drastycznie poprawia jakość i aktualność generowanych treści.
Automatyzacja z AI wykorzystuje bazy wektorowe do przechowywania "pamięci" agentów AI, umożliwiając im kontekstowe podejmowanie decyzji na podstawie historycznych danych.
Porównanie typów baz danych
Porównanie trzech głównych typów baz danych: relacyjne, nierelacyjne i wektorowe
Struktura danych i schemat
Relacyjne bazy danych wymagają predefiniowanego schematu z tabelami, kolumnami i typami danych. Każda zmiana struktury wymaga migracji, co może być czasochłonne w dużych systemach.
NoSQL oferuje elastyczność schematu - dokumenty w tej samej kolekcji mogą mieć różne struktury. Umożliwia to szybką adaptację do zmieniających się wymagań biznesowych.
Bazy wektorowe koncentrują się na wektorach jako głównym typie danych, ale pozwalają na przechowywanie metadanych w elastycznej formie. Schemat jest minimalny - głównie wymiary wektora i opcjonalne metadane.
Spójność, transakcje, ACID vs CAP theorem
ACID (Atomicity, Consistency, Isolation, Durability) to właściwości zapewniające silną spójność w relacyjnych bazach danych. Każda transakcja jest albo w pełni wykonana, albo w ogóle, co gwarantuje integralność danych.
CAP theorem (Consistency, Availability, Partition tolerance) opisuje ograniczenia systemów rozproszonych. Według tego twierdzenia, system może zapewnić jednocześnie tylko dwie z trzech właściwości:
- Consistency - wszystkie węzły mają te same dane w tym samym czasie
- Availability - system zawsze odpowiada na zapytania
- Partition tolerance - system działa mimo awarii komunikacji między węzłami
NoSQL często wybiera dostępność i tolerancję na partycje (AP), stosując eventual consistency. Dane są spójne w dłuższej perspektywie, ale mogą być tymczasowo niespójne między węzłami.
Skalowalność: pozioma/pionowa
Skalowanie pionowe (scale-up) polega na zwiększaniu mocy pojedynczego serwera - więcej RAM, szybszy procesor, większy dysk. Relacyjne bazy danych tradycyjnie polegają na tym podejściu.
Skalowanie poziome (scale-out) oznacza dodawanie kolejnych serwerów do klastra. NoSQL został zaprojektowany z myślą o tym podejściu, umożliwiając liniowe zwiększanie pojemności i wydajności.
Bazy wektorowe łączą oba podejścia - mogą działać na pojedynczych maszynach (pgvector) lub w klastrach rozproszonych (Milvus), zależnie od skali zastosowania.
Wydajność: latency, operacje zapisu/odczytu, zapytania złożone
Relacyjne bazy danych oferują doskonałą wydajność dla złożonych zapytań z JOINami i agregacjami. PostgreSQL konsistentnie przewyższa MongoDB w różnych typach zapytań o 4-15 razy.
NoSQL optymalizuje wydajność dla określonych wzorców dostępu. Redis osiąga latencję w mikrosekundach dla operacji klucz-wartość, podczas gdy Cassandra zapewnia wysoką przepustowość zapisów.
Bazy wektorowe są zoptymalizowane pod wyszukiwanie podobieństwa. Nowoczesne algorytmy jak HNSW pozwalają na zapytania w czasie rzeczywistym nawet w bazach z milionami wektorów.
Zastosowania praktyczne (use-cases)
Automatyzacja procesów - dlaczego baza danych jest fundamentem
W kontekście automatyzacji procesów biznesowych, wybór odpowiedniej bazy danych decyduje o skuteczności całego workflow. Platformy jak n8n integrują się z różnymi typami baz danych, aby zapewnić optymalne przechowywanie i przetwarzanie danych w zautomatyzowanych procesach.
Relacyjne bazy danych sprawdzają się w automatyzacji procesów transakcyjnych - zarządzanie zamówieniami, faktury, systemy CRM. Gdy workflow wymaga silnej spójności danych i złożonych relacji między encjami, SQL pozostaje najlepszym wyborem.
NoSQL idealnie nadaje się do automatyzacji procesów związanych z dużymi wolumenami danych - przetwarzanie logów, agregacja metryki, obsługa eventów. MongoDB może przechowywać różnorodne dokumenty generowane przez różne kroki workflow.
Bazy wektorowe rewolucjonizują automatyzację opartą na AI. Mogą przechowywać embeddingi dokumentów firmowych, umożliwiając inteligentnym chatbotom odpowiadanie na pytania pracowników w oparciu o firmową wiedzę.
AI/embedding/semantyczne wyszukiwanie
Nowoczesne zastosowania AI wymagają zaawansowanych możliwości wyszukiwania i analizy danych. Bazy wektorowe są niezbędne w:
Chatbotach korporacyjnych wykorzystujących RAG do odpowiadania na pytania na podstawie dokumentacji firmowej. System wektoryzuje pytanie użytkownika, znajduje podobne fragmenty w bazie wiedzy i generuje odpowiedź.
Systemach rekomendacji analizujących preferencje użytkowników i charakterystyki produktów w przestrzeni wektorowej. E-commerce może rekomendować produkty na podstawie podobieństwa embeddingów.
Analizie sentymentu w mediach społecznościowych, gdzie embeddingi tekstów umożliwiają klasyfikację opinii bez konieczności ręcznego tagowania.
Systemy transakcyjne, CRM, e-commerce
Systemy transakcyjne wymagają właściwości ACID dla zapewnienia integralności finansowej. Bankowość, systemy płatności i e-commerce nie mogą tolerować niespójności danych - relacyjne bazy danych pozostają tu standardem.
CRM (Customer Relationship Management) często łączy różne podejścia. Podstawowe dane klientów i transakcje przechowywane są w SQL, dokumenty i notatki w NoSQL, a analizy preferencji wykorzystują bazy wektorowe do personalizacji.
E-commerce wykorzystuje hybrydowe podejście:
- PostgreSQL dla zarządzania produktami, zamówieniami i płatnościami
- Redis dla cache'owania sesji i popularnych produktów
- Elasticsearch dla wyszukiwania pełnotekstowego
- Bazy wektorowe dla rekomendacji i wyszukiwania podobnych produktów
Kiedy wybrać który typ bazy danych
Kryteria decyzyjne: dane, obciążenie, skalowanie, budżet, wymagania spójności
Wybierz relacyjne bazy danych gdy:
- Wymagasz silnej spójności transakcji (systemy finansowe, e-commerce)
- Dane mają wyraźną strukturę relacyjną
- Potrzebujesz złożonych zapytań z JOINami
- Zespół ma doświadczenie z SQL
- Budżet pozwala na skalowanie pionowe
Wybierz NoSQL gdy:
- Pracujesz z big data lub różnorodnymi typami danych
- Wymagasz elastyczności schematu
- Priorytetem jest skalowalność pozioma
- Eventual consistency jest akceptowalna
- Potrzebujesz wysokiej dostępności
Wybierz bazy wektorowe gdy:
- Implementujesz funkcjonalności AI/ML
- Potrzebujesz wyszukiwania semantycznego
- Budujesz systemy rekomendacji
- Pracujesz z embeddingami z modeli językowych
- Wymagasz wyszukiwania podobieństwa
Hybrydowe podejścia: łączenie SQL, NoSQL, bazy wektorowe
Nowoczesne aplikacje często wykorzystują polyglot persistence - różne bazy danych do różnych zadań:
E-commerce może używać:
- PostgreSQL dla zamówień i płatności (spójność transakcyjna)
- MongoDB dla katalogu produktów (elastyczność schematu)
- Redis dla cache'a i sesji (szybkość dostępu)
- Pinecone dla rekomendacji (wyszukiwanie semantyczne)
Platforma automatyzacji może łączyć:
- MySQL dla konfiguracji workflow i metadanych
- MongoDB dla przechowywania zróżnicowanych danych z API
- Vector database dla AI-powered decyzji w procesach
Kluczowe aspekty hybrydowego podejścia:
- Konsystencja danych między różnymi systemami
- Synchronizacja i ETL/ELT procesy
- Monitorowanie wielu technologii
- Kompetencje zespołu w różnych obszarach
Podsumowanie i zapowiedź kolejnych artykułów szczegółowych
Wybór odpowiedniego typu bazy danych to strategiczna decyzja wpływająca na wydajność, skalowalność i możliwości rozwoju aplikacji. Relacyjne bazy danych pozostają fundamentem systemów wymagających silnej spójności, NoSQL dominuje w świecie big data i aplikacji rozproszonych, a bazy wektorowe otwierają nowe możliwości w obszarze AI i automatyzacji inteligentnej.
Kluczem do sukcesu jest zrozumienie specyfiki każdego typu i dopasowanie technologii do rzeczywistych potrzeb biznesowych. Często optymalne rozwiązanie wymaga hybrydowego podejścia łączącego różne typy baz danych.
W kolejnych artykułach szczegółowo omówimy:
- PostgreSQL w praktyce - konfiguracja, optymalizacja i zaawansowane funkcje
- MongoDB dla aplikacji webowych - modelowanie danych i najlepsze praktyki
- Implementacja baz wektorowych - od wyboru narzędzia po integrację z AI
- Automatyzacja z bazami danych - praktyczne workflow w n8n z różnymi typami baz
Najczęściej zadawane pytania:
Czy baza wektorowa może zastąpić relacyjną? Nie, bazy wektorowe są specjalistyczne i służą głównie do wyszukiwania podobieństwa. Relacyjne bazy danych pozostają niezbędne do zarządzania strukturalnymi danymi biznesowymi.
Czy NoSQL oznacza brak schematu? Nie całkowicie. NoSQL oferuje elastyczność schematu, ale nie oznacza braku struktury. Bazy jak MongoDB pozwalają na opcjonalne schematy i walidację danych.
Czy wektorowa baza danych ma sens w małych projektach? Tak, jeśli projekt wykorzystuje AI lub wymaga wyszukiwania semantycznego. Rozwiązania jak pgvector pozwalają na start z małą skalą przy użyciu znanej technologii PostgreSQL.
Zobacz też
Wiesz już, który typ bazy wybrać do swojego projektu — ale żeby naprawdę z niej skorzystać, trzeba opanować język zapytań. Nasza seria SQL od podstaw prowadzi od pierwszego SELECT, przez JOIN-y i GROUP BY, aż po optymalizację planów wykonania w MySQL i PostgreSQL. Jest celowana w tych, którzy relacyjną bazę mają już wybraną i chcą z niej wyciągnąć maksimum.


